Deep Convolutional Generative Adversarial Networks: Review and Implementation using PyTorch C++ API
Contents
I’m pleased to start a series of blogs on GANs and their implementation with PyTorch C++ API. We’ll be starting with one of the initial GANs - DCGANs (Deep Convolutional Generative Adversarial Networks).

The authors (Soumith Chintala, Radford and Luke Metz) in this Seminal Paper on DCGANs introduced DCGANs to the world like this:
We introduce a class of CNNs called deep convolutional generative adversarial networks (DCGANs), that have certain architectural constraints, and demonstrate that they are a strong candidate for unsupervised learning. Training on various image datasets, we show convincing evidence that our deep convolutional adversarial pair learns a hierarchy of representations from object parts to scenes in both the generator and discriminator. Additionally, we use the learned features for novel tasks - demonstrating their applicability as general image representations.
Even though, the introduction to DCGANs is quite lucid, but here are some points to note:
- DCGANs are a class of Convolutional Neural Networks.
- They are a strong candidate for Unsupervised Learning.
- They are applicable as general image representations as well.
Let’s go ahead and see what exactly is DCGAN?
Introduction to DCGAN
At the time when this paper was released, there was quite a focus on Supervised Learning. The paper aimed at bridging the gap between Unsupervised Learning and Supervised Learning. DCGANs are a way to understand and extract important feature representations from a dataset and generate good image representations by training.
Any Generative Adversarial Network has 2 major components: a Generator and a Discriminator. The tasks for both of them are simple.
- Generator: Generates Images similar to the data distribution such that Discriminator can not distinguish it with the original data.
- Discriminator: Discriminator has a task on accurately distinguishing between the image from the generator and from the data distribution. It basically has to recognize an image as fake or real, correctly.
Both Generator and Discriminator tasks can be represented beautifully with the following equation:
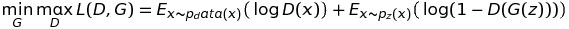
The above equation, shows how the Generator and Discriminator plays min-max game.
- The Generator tries to minimize the loss function. It follows up with two cases:
- When the data is from the data distribution: Generator has a task of forcing the Discriminator to predict the data as fake.
- When data is from the Generator: Generator has a task of forcing the Discriminator to predict the data as real.
- The Discriminator tries to maximize the loss function. It follows up with two cases:
- When the data is from the data distribution: Discriminator tries to predict the data as real.
- When the data is from the Generator: Discriminator tries to predict the data as fake.
Fundamentally, the Generator is trying to fool the Discriminator and the Discriminator is trying not to get fooled with. Because of it’s analogy, it’s also called a police-thief game. (Police is the Discriminator and thief is the Generator).
We have good enough discussion on GANs, to kickstart discussion on DCGANs. Let’s go ahead and see what changes they proposed on common CNNs:
Changes in the Generator:
- Spatial Pooling Layers such as MaxPool Layers were replaced with Fractional-Strided Convolutions (a.k.a Transposed Convolutions). This allows the network to learn it’s own spatial downsampling, instead of explicitly mentioning the downsampling parameters by Max Pooling.
- Use BatchNorm in the Generator.
- Remove Fully Connected layers for deeper architectures.
- Use ReLU activation function for all the layers except the output layer (which uses Tanh activation function).
Changes in the Discriminator:
- Spatial Pooling Layers such as MaxPool layers were replaced with Strided Convolutions.
- Use BatchNorm in the Discriminator.
- Remove FC layers for deeper architectures.
- Use LeakyReLU activation function for all the layers in the Discriminator.
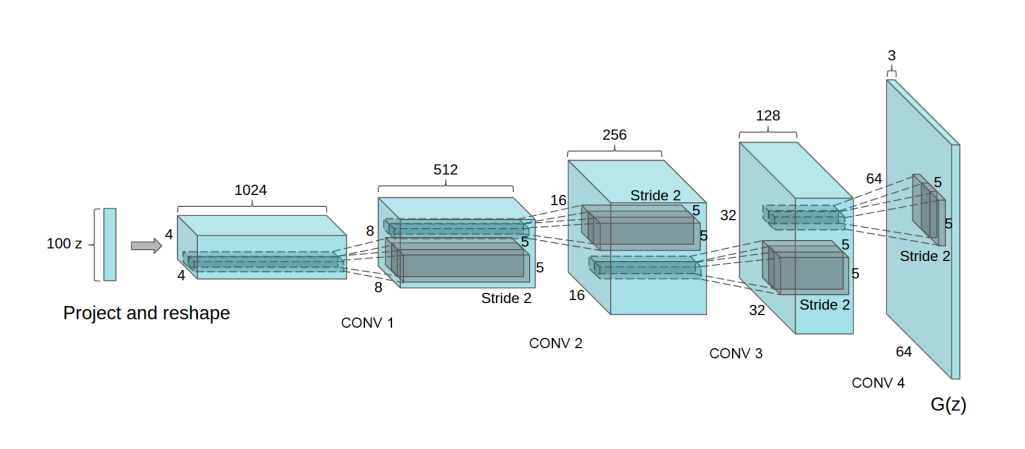
As you would note in the above architecture, there is absence of spatial pooling layers and fully connected layers.
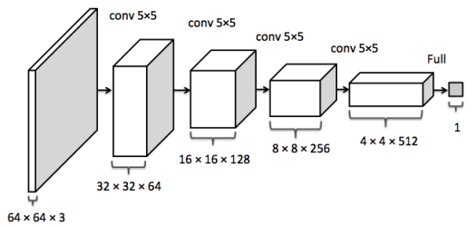
Notably again, there are no pooling and fully connected layers (except the last layer).
Let’s start with defining the architectures of both Generators and Discriminators using PyTorch C++ API. I used the Object Oriented approach by making class, each for Generator and Discriminator. Note that each of them are a type of CNNs, and also inherit functions (or methods) from torch::nn::Module class.
As mentioned before, Generator uses Transposed Convolutional Layers and has no pooling and FC layers. It also uses ReLU Activation Function (except the last layer). The parameters used for the Generator include:
dataroot: (type:std::string) Path of the dataset’s root directory.workers: (type:int) Having moreworkerswill increase CPU memory usage. (Check this link for more details)batch_size: (type:int) Batch Size to consider.image_size: (type:int) Size of the image to resize it to.nc: (type:int) Number of channels in the Input Image.nz: (type:int) Length of latent vector, from which the input image is taken.ngf: (typeint) Depth of feature maps carried through the generator.num_epochs: (typeint) Number of epochs for which the model is trained.lr: (typefloat) Learning Rate for training. Authors described it to be 0.0002beta1: (type:float) Hyperparameter for Optimizer used (Adam).ngpu: (type:int) Number of GPUs available to use. (use0if no GPU available)
class Generator : public torch::nn::Module {
private:
std::string dataroot;
int workers;
int batch_size;
int image_size;
int nc;
int nz;
int ngf;
int num_epochs;
float lr;
float beta1;
int ngpu;
public:
torch::nn::Sequential main;
Generator(std::string dataroot_ = "data/celeba", int workers_ = 2, int batch_size_ = 128, int image_size_ = 64, int nc_ = 3, int nz_ = 100, int ngf_ = 64, int ndf_ = 64, int num_epochs_ = 5, float lr_ = 0.0002, float beta1_ = 0.5, int ngpu_ = 0) {
// Set the arguments
dataroot = dataroot_;
workers = workers_;
batch_size = batch_size_;
image_size = image_size_;
nc = nc_;
nz = nz_;
ngf = ngf_;
ndf = ndf_;
num_epochs = num_epochs_;
lr = lr_;
beta1 = beta1_;
ngpu = ngpu_;
main = torch::nn::Sequential(
torch::nn::Conv2d(torch::nn::Conv2dOptions(nz, ngf*8, 4).stride(1).padding(0).with_bias(false).transposed(true)),
torch::nn::BatchNorm(ngf*8),
torch::nn::Functional(torch::relu),
torch::nn::Conv2d(torch::nn::Conv2dOptions(ngf*8, ngf*4, 4).stride(2).padding(1).with_bias(false).transposed(true)),
torch::nn::BatchNorm(ngf*4),
torch::nn::Functional(torch::relu),
torch::nn::Conv2d(torch::nn::Conv2dOptions(ngf*4, ngf*2, 4).stride(2).padding(1).with_bias(false).transposed(true)),
torch::nn::BatchNorm(ngf*2),
torch::nn::Functional(torch::relu),
torch::nn::Conv2d(torch::nn::Conv2dOptions(ngf*2, ngf, 4).stride(2).padding(1).with_bias(false).transposed(true)),
torch::nn::BatchNorm(ngf),
torch::nn::Functional(torch::relu),
torch::nn::Conv2d(torch::nn::Conv2dOptions(ngf, nc, 4).stride(2).padding(1).with_bias(false).transposed(true)),
torch::nn::Functional(torch::tanh)
);
}
torch::nn::Sequential main_func() {
// Returns Sequential Model of the Generator
return main;
}
};
Note how we used Transposed Convolution, by passing .transposed(true).
Similarly, we define the class for Discriminator.
class Discriminator : public torch::nn::Module {
private:
std::string dataroot;
int workers;
int batch_size;
int image_size;
int nc;
int nz;
int ndf;
int num_epochs;
float lr;
float beta1;
int ngpu;
public:
torch::nn::Sequential main;
Discriminator(std::string dataroot_ = "data/celeba", int workers_ = 2, int batch_size_ = 128, int image_size_ = 64, int nc_ = 3, int nz_ = 100, int ngf_ = 64, int ndf_ = 64, int num_epochs_ = 5, float lr_ = 0.0002, float beta1_ = 0.5, int ngpu_ = 1) {
dataroot = dataroot_;
workers = workers_;
batch_size = batch_size_;
image_size = image_size_;
nc = nc_;
nz = nz_;
ngf = ngf_;
ndf = ndf_;
num_epochs = num_epochs_;
lr = lr_;
beta1 = beta1_;
ngpu = ngpu_;
main = torch::nn::Sequential(
torch::nn::Conv2d(torch::nn::Conv2dOptions(nc, ndf, 4).stride(2).padding(1).with_bias(false)),
torch::nn::Functional(torch::leaky_relu, 0.2),
torch::nn::Conv2d(torch::nn::Conv2dOptions(ndf, ndf*2, 4).stride(2).padding(1).with_bias(false)),
torch::nn::BatchNorm(ndf*2),
torch::nn::Functional(torch::leaky_relu, 0.2),
torch::nn::Conv2d(torch::nn::Conv2dOptions(ndf*2, ndf*4, 4).stride(2).padding(1).with_bias(false)),
torch::nn::BatchNorm(ndf*4),
torch::nn::Functional(torch::leaky_relu, 0.2),
torch::nn::Conv2d(torch::nn::Conv2dOptions(ndf*4, ndf*8, 4).stride(2).padding(1).with_bias(false)),
torch::nn::BatchNorm(ndf*8),
torch::nn::Functional(torch::leaky_relu, 0.2),
torch::nn::Conv2d(torch::nn::Conv2dOptions(ndf*8, 1, 4).stride(1).padding(0).with_bias(false)),
torch::nn::Functional(torch::sigmoid)
);
}
torch::nn::Sequential main_func() {
return main;
}
};
We can initialize these networks as shown below:
// Uses default arguments if no args passed
Generator gen = Generator()
Discriminator dis = Discriminator()
torch::nn::Sequential gen_model = gen.main_func()
torch::nn::Sequential dis_model = dis.main_func()
In case you are using a GPU, you can convert the models:
torch::Device device = torch::kCPU;
if(torch::cuda::is_available()) {
device = torch::kCUDA;
}
gen_model->to(device);
dis_model->to(device);
Note on Data Loading: In the past blogs, I’ve discussed on loading custom data. Please refer to the previous blogs for a quick review on loading data.
Let’s go ahead and define optimizers and train our model. We use the parameters defined by the authors, for optimizer (Adam, beta = 0.5) and learning rate of 2e-4.
torch::optim::Adam gen_optimizer(gen_model->parameters(), torch::optim::AdamOptions(2e-4).beta1(0.5));
torch::optim::Adam dis_optimizer(dis_model->parameters(), torch::optim::AdamOptions(2e-4).beta1(0.5));
Time to write our training code. We are using CelebA dataset which looks like this:

The dataset is huge, and contains 10,177 number of identities and around ~200k number of face images. It also contains annotations, but since GANs are a way of unsupervised learning, so they don’t actually consider annotations. Before we move on, we’ll see a quick step by step review on training the Discriminator and Generator simultaneously:
- Step-1: Train Discriminator. Remember from above, the discriminator tries to maximize the loss function such that it predicts the fake images as fake and real images as real.
- As the first step for every training process, we set the gradients to zero. This helps in calculating correct gradients, and not getting confused with gradients stored in the previous iteration.
- First calculate discriminator loss on real images (that is, data from our dataset). We do this by getting data from the batch and labels as anything between 0.8 and 1.0 (since it’s real, we approximate it from 0.8 to 1.0).
- Do a forward pass to the discriminator network, and calculate output on the batch of data from our dataset.
- Calculate loss by using
torch::binary_cross_entropyand backpropagate the loss. - We now calculate discriminator loss on fake images (that is, data from the generator). For this, we take a noise of shape similar to the batch of data, and pass that noise to the generator.
- The labels are given zero values (as the images are fake).
- Again, calculate the loss by using
torch::binary_cross_entropyand backpropagate the loss. - Sum both the losses, discriminator loss on real images + discriminator loss on fake images. This will be our discriminator loss.
- We then update our parameters using the optimizer.
- Step-2: Train Generator. The task of a Generator is to minimize the loss function. Since it has to produce images which can fool the discriminator, so it only has to consider fake images.
- As the first step for every training process, we set the gradients to zero. This helps in calculating correct gradients, and not getting confused with gradients stored in the previous iteration.
- We use the fake images produced in the Step-1 and pass it to the discriminator.
- Fill the labels with 1. (since generator wants to fool the discriminator, by making it predict as real images).
- Calculate loss, by using
torch::binary_cross_entropyand backpropagate the loss. - Update the parameters using optimizer of the Generator.
for(int epoch=1; epoch<=10; epoch++) {
// Store batch count in a variable
int batch_count = 0;
// You can use torch::data::Example<>& batch: *data_loader
for(auto& batch: *data_loader) {
// Step-1: Train the Discriminator
// Set gradients to zero
netD->zero_grad();
// Calculating discriminator loss on real images
torch::Tensor images_real = batch.data.to(device);
torch::Tensor labels_real = torch::empty(batch.data.size(0), device).uniform_(0.8, 1.0));
// Do a forward pass to the Discriminator network
torch::Tensor output_D_real = netD->forward(images_real);
// Calculate the loss
torch::Tensor loss_real_D = torch::binary_cross_entropy(output_D_real, labels_real);
loss_real_D.backward();
// Calculate discriminator loss on fake images
// Generate noise and do forward pass to generate fake images
torch:Tensor fake_random = torch::randn({batch.data.size(0), args.nz, 1, 1}, device);
torch::Tensor images_fake = netG->forward(images_fake);
torch::Tensor labels_fake = torch::zeros(batch.data.size(0), device);
// Do a forward pass to the Discriminator network
torch::Tensor output_D_fake = netD->forward(images_fake);
// Calculate the loss
torch::Tensor loss_fake_D = torch::binary_cross_entropy(output_D_fake, labels_fake);
loss_fake_D.backward();
// Total discriminator loss
torch::Tensor loss_discriminator = loss_real_D + loss_fake_D;
// Update the parameters
dis_optimizer.step();
// Step-2: Train the Generator
// Set gradients to zero
netG->zero_grad();
// calculating generator loss on fake images
// Change labels_fake from all zeros to all ones
labels_fake.fill_(1);
// Do forward pass to the Discriminator on the fake images generated above
torch::Tensor output_G_fake = netD->forward(images_fake);
// Calculate loss
torch::Tensor loss_generator = torch::binary_cross_entropy(output_G_fake, labels_fake);
loss_generator.backward();
// Update the parameters
gen_optimizer.step();
std::cout << "Epoch: " << epoch << ", Batch: " << batch_count << ", Gen Loss: " << loss_generator.item<float>() << ", Discriminator Loss: " << loss_discriminator.item<float>() << std::endl;
batch_count++;
}
}
We are all set to train our first DCGAN in C++ using Libtorch. How amazing it is?
In the coming blog, I’ll share the results and answer a few common questions on the architecture of DCGAN.
Acknowledgement and References
I would like to thank Will Feng and Piotr for their useful suggestions. The code used in this blog, is partially analogous to the official PyTorch examples repo on DCGAN using LibTorch. I’ve also referred the original paper by Soumith Chintala and others. The sources of reference images (for Network architectures) have been acknowledged in the captions of respective images.